简介
设计实验的话,使用到的技术需要具有足够的代表性与覆盖面,同时需要由浅入深循序渐进。于是我设计了基于mnist手写数据集的实验,通过这次实验,你可以加深对以下知识的理解(打*为非必学):
-
pytorch框架
- 加载训练集和测试集
- 批训练(Batch Training)
- torch.tensor和numpy与array的互相转换
- 使用torch.nn.Sequential快速搭建神经网络
-
python语法
- 将不同模块分别封装并在ui类中实例化
- *使用多线程分配训练任务防止用户界面卡死无法使用其他功能
-
卷积神经网络
-
numpy在神经网络中数据转换的应用
-
*使用TSNE方法将神经网络最后一层投射到二维平面直观观察
-
*使用Qt Designer + pyQt5设计用户界面
-
*使用PIL中的Image包对图片进行处理
最终效果如下图所示:

使用mnist数据集进行训练
加载数据集
我们选择了一个已经广泛应用于入门学习的手写数字数据集——MNIST。引用eleclike 的一句话帮你了解MNIST:就好像每种程序语言都有一个helloworld的例子,mnist则是机器学习领域的helloworld,该数据集中的图片表示0~9的手写阿拉伯数字。mnist包含一个训练集(一个训练图片文件和一个训练标签文件)和一个测试集(一个测试图片文件,一个测试标签文件),其中训练集有60000个样本,测试集有10000个样本。
它已经被内置在了torchvision.datasets中,可以直接下载。在我们的训练模块中,由于已经下载过的话不必再来一次,所以使用os.path.exists()对路径进行检验,若是已经下载过数据集则不再进行下载操作。注意下载的数据共105MB。
import os
import torch
import torchvision
DOWNLOAD_MNIST = False
if not (os.path.exists('./mnist/')) or not os.listdir('./mnist/'):
# not mnist dir or mnist is empyt dir
DOWNLOAD_MNIST = True
train_data = torchvision.datasets.MNIST(
root='./mnist/',
train=True, # this is training data
transform=torchvision.transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]
download=DOWNLOAD_MNIST,
)
注意原本的训练集是28*28的手写数字灰度图,我们需要使用torchvision.transforms.ToTensor()对其进行格式转换,类似于将图片(PIL.Image)翻译成神经网络能读懂的张量(torch.tensor)。至此,训练数据下载完毕。
值得注意的是,测试数据集也是通过torchvision.datasets.MNIST()加载的,只需将train设置为False状态即可。进一步地,从数据中分出用于测试的图片数据(如手写阿拉伯数字“5”的图片转换为的tensor)以及对于每张图片的标注(如对应手写图片5的标注就是一个只含有一个数字“5”的tensor)。由于在训练过程中需要多次反馈当前模型的准确率,为了节省时间我们只取前测试集中的前2000个样本,代码如下:
from torch.autograd import Variable
# convert test data into Variable, pick 2000 samples to speed up testing
test_data = torchvision.datasets.MNIST(root='./mnist/', train=False)
test_x = Variable(torch.unsqueeze(test_data.test_data, dim=1)).type(torch.FloatTensor)[
:2000] / 255. # shape from (2000, 28, 28) to (2000, 1, 28, 28), value in range(0,1)
test_y = test_data.test_labels[:2000]
注意准备进行训练的数据值要进行特征缩放(归一化),这样可以加快求解过程中参数的收敛速度。由于灰度图像是在单个电磁波频谱如可见光内测量每个像素的亮度得到的,用于显示的灰度图像通常用每个采样像素8位的非线性尺度来保存,这样可以有256级灰度,也就是用值为0~255的数值表示每个采样像素,对tensor的每个值除以255.0即得到归一化后的数据(所有数值均在0~1)。
查看数据集
拿到所有的数据之后,我们可以先验验货。在这里,我们打印训练数据集的大小、标注集的大小以及训练图片的第一张。你可以通过查看官方文档或者通过pycharm等IDE查看这些数据的具有的所有属性并打印查看。
import matplotlib.pyplot as plt
# plot one example
print(train_data.train_data.size()) # (60000, 28, 28)
print(train_data.train_labels.size()) # (60000)
plt.imshow(train_data.train_data[0].numpy(), cmap='gray')
plt.title('%i' % train_data.train_labels[0])
plt.show()
运行代码后我们得到了如下的结果,可以看出,训练数据集是由60000张28*28的图片组成的,每张图片对应了一个它的标注(即图上的手写数字是几),第一张图像是手写数字5:

建立卷积神经网络模型
首先引用维基百科介绍一下卷积神经网络(更深入的介绍点击原文):
卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,[1]对于大型图像处理有出色表现。
卷积神经网络由一个或多个卷积层和顶端的全连通层(对应经典的神经网络)组成,同时也包括关联权重和池化层(pooling layer)。这一结构使得卷积神经网络能够利用输入数据的二维结构。与其他深度学习结构相比,卷积神经网络在图像和语音识别方面能够给出更好的结果。这一模型也可以使用反向传播算法进行训练。相比较其他深度、前馈神经网络,卷积神经网络需要考量的参数更少,使之成为一种颇具吸引力的深度学习结构。
在这里我们建立了这样的卷积神经网络模型:
import torch.nn as nn
# CNN model
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential( # input shape (1, 28, 28)
nn.Conv2d(
in_channels=1, # input height
out_channels=16, # n_filters
kernel_size=5, # filter size
stride=1, # filter movement/step
padding=2,
# if want same width and length of this image after con2d, padding=(kernel_size-1)/2 if stride=1
), # output shape (16, 28, 28)
nn.ReLU(), # activation
nn.MaxPool2d(kernel_size=2), # choose max value in 2x2 area, output shape (16, 14, 14)
)
self.conv2 = nn.Sequential( # input shape (16, 14, 14)
nn.Conv2d(16, 32, 5, 1, 2), # output shape (32, 14, 14)
nn.ReLU(), # activation
nn.MaxPool2d(2), # output shape (32, 7, 7)
)
self.out = nn.Linear(32 * 7 * 7, 10) # fully connected layer, output 10 classes
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1) # flatten the output of conv2 to (batch_size, 32 * 7 * 7)
output = self.out(x)
return output, x # return x for visualization
cnn = CNN()
print(cnn) # net architecture
通过print方法我们可以看到这个卷积神经网络的结构:

其中torch.nn.Sequential是一个Sequential容器,模块将按照构造函数中传递的顺序添加到模块中,可以达到快速搭建神经网络的目的。参见pytorch官方文档可以详细地看到使用传统方法建立神经网络和使用Sequential搭建神经网络的代码区别。
可以看到,本次用到的卷积神经网络由两个由Sequential构建的神经网络组成。其中均包含了卷积层、线性整流(即Rectified Linear Units, ReLU)层(激活函数)以及池化层(是一种形式的降采样。有多种不同形式的非线性池化函数,而其中“最大池化(Max pooling)”是最为常见的。它是将输入的图像划分为若干个矩形区域,对每个子区域输出最大值)。在训练过程中,还将引入损失函数(loss function)用于决定训练过程如何来“惩罚”网络的预测结果和真实结果之间的差异。
注意最终输出的是一个10维的向量,因为需要解决的是总共有10类的分类问题(手写数字0~9)。在完成训练后,我们只需获取神经网络对应某张图片输入的输出,找出10维向量中的最大值即可找出神经网络推测的最可能的手写数字答案。
准备训练
在这里我们需要做好三样准备:
- 通过torch.utils.data.DataLoader加载训练数据并实现批训练
- 定义优化器
- 定义损失函数
首先,按批加载训练数据,并将每批的数据打乱,以获得更好的训练效果。
import torch.utils.data as Data
BATCH_SIZE = 50
train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
然后定义优化器,用于在训练的过程中优化网络的所有参数。注意这里使用了Adam,想深入了解我推荐阅读莫烦在这里的教程,在这里引用莫烦的一张图说明原理,它相较于普通的随机梯度下降拥有更快的收敛速度。
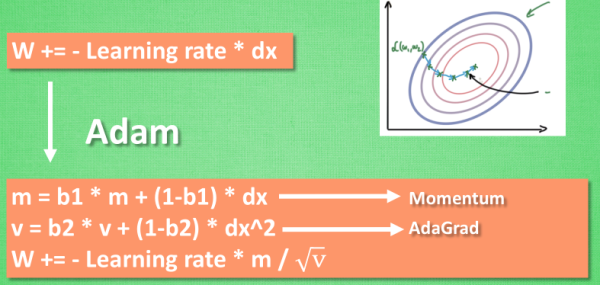
optimizer = torch.optim.Adam(cnn.parameters(), lr=LR) # optimize all cnn parameters
然后定义损失函数,用于决定训练过程如何来“惩罚”网络的预测结果和真实结果之间的差异,它通常是网络的最后一层。各种不同的损失函数适用于不同类型的任务。在本次实验中我们使用交叉熵损失函数,常常被用于在K个类别中选出一个。
loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted
至此,我们已经具备了进行训练的所有前置条件,接下来我们就可以开始训练了。
训练与测试
设置迭代次数和学习率
迭代次数和学习率是机器学习中十分重要的两个超级参数(即一般情况下以全大写的形式声明在代码顶端,便于修改)。首先明确一下这两个概念:
迭代次数(Epoch):1个epoch等于使用训练集中的全部样本训练一次;一个epoch = 所有训练样本的一个正向传递和一个反向传递
学习率(Learning rate):作为监督学习以及深度学习中重要的超参,其决定着目标函数能否收敛到局部最小值以及何时收敛到最小值。合适的学习率能够使目标函数在合适的时间内收敛到局部最小值。
在这里,为了节约时间我们设置迭代次数为1(增大会延长训练时间且很可能会获得更好的训练结果),学习率为0.001(增大可能会减小训练的精度,减小会延长训练时间)。
EPOCH = 1 # train the training data n times, to save time, we just train 1 epoch
LR = 0.001 # learning rate
进行训练
使用循环结构进行训练,注意train_loader是从DataLoader来的,不能使用下标访问,要使用枚举函数enumerate()。代码如下:
for epoch in range(EPOCH):
for step, (x, y) in enumerate(train_loader): # gives batch data, normalize x when iterate train_loader
b_x = Variable(x) # batch x
b_y = Variable(y) # batch y
output = cnn(b_x)[0] # cnn output
loss = loss_func(output, b_y) # cross entropy loss
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
我们使用到了torch.autograd.Variable数据类型来取出每一批数据并输入神经网络,通过optimizer逐步优化网络,通过损失函数将输出与正确答案对比判定误差。
进行测试
为了能更多地反应训练的效果,我们每训练五十批数据(即50*50=2500张图片)进行一次测试,选用测试集中的前2000个样例进行测试,并计算准确率以及误差函数值输出到控制台。
if step % 50 == 0:
test_output, last_layer = cnn(test_x)
pred_y = torch.max(test_output, 1)[1].data.squeeze()
pl = pred_y.tolist()
tl = test_y.tolist()
matched = 0
for i in range(len(pl)):
if pl[i] == tl[i]:matched+=1
accuracy = float(matched / test_y.size(0))
print('Epoch: ', epoch, '| Iteration: ', step, '| train loss: %.4f' % loss.data.item(), '| test accuracy: %.2f' % accuracy)
记录测试集标签(手写数字的真实值)中与网络输出值中吻合的数目,我们就可以得到当前的准确率。这是我进行训练的记录,可以看到准确率在不断上升:
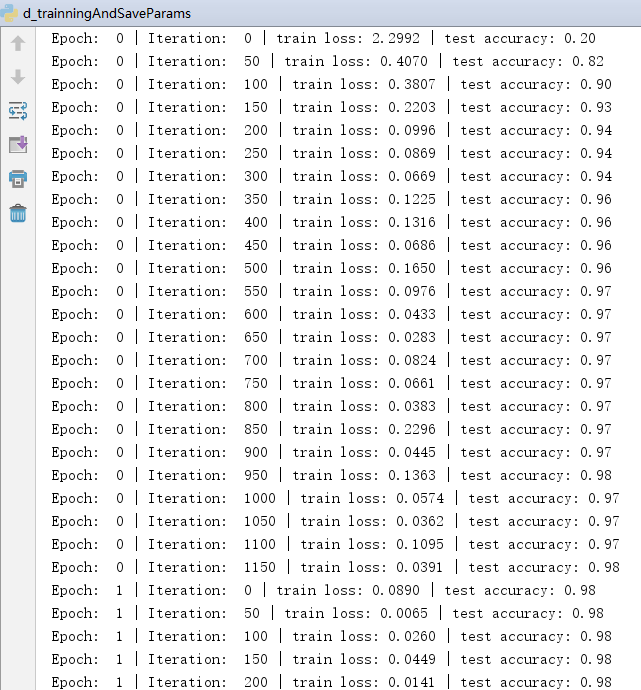
*直观观察
使用TSNE方法将神经网络最后一层投射到二维平面直观观察:
from matplotlib import cm
try:
from sklearn.manifold import TSNE; HAS_SK = True
except:
HAS_SK = False; print('Please install sklearn for layer visualization')
def plot_with_labels(lowDWeights, labels):
plt.cla()
X, Y = lowDWeights[:, 0], lowDWeights[:, 1]
for x, y, s in zip(X, Y, labels):
c = cm.rainbow(int(255 * s / 9));
plt.text(x, y, s, backgroundcolor=c, fontsize=9)
plt.xlim(X.min(), X.max());
plt.ylim(Y.min(), Y.max());
plt.title('Visualize last layer');
plt.show();
plt.pause(0.01)
if HAS_SK:
# Visualization of trained flatten layer (T-SNE)
tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)
plot_only = 500
low_dim_embs = tsne.fit_transform(last_layer.data.numpy()[:plot_only, :])
labels = test_y.numpy()[:plot_only]
plot_with_labels(low_dim_embs, labels)
实现识别鼠标手写数字
目标
不再以图片作为输入,而是以鼠标写数字作为输入,通过程序将其转换为张量格式作为输入,获取输出后反馈给使用者。在下一步,我还计划设计将用户手写的数字和键入的标签值打包作为训练集进行训练,进而实现改善神经网络的目的。
ui搭建
我设计了两个窗口实现这个程序,一个窗口作为画板,用来接受鼠标输入;另一个作为控制板,设置了以下几个模块:
- 监视器:监视当前的动作,便于debug以及监视各个步骤执行速度,带有clear键用于清屏
- 提交识别按钮:将当前画面的图形转为张量输入到神经网络,获取输出后展示在监视器
- 清空画板按钮:将画板中存储的输入图形清除,以便重复使用,再次书写、识别等
- 提交训练按钮:将画板中的图形和输入框中输入的数字打包作为训练数据传入网络进一步进行训练(未完工)
画板
这里参考了PyLearn的博客,在博客中博主由简入繁地使用PyQt5制作了4个功能越发完善体验越来越好的画板,我选用了其中的第四个作为我的画板。实现原理大概是:在按下鼠标的时候开始监视鼠标的轨迹并将鼠标经过的坐标点都保存到一个元组中,当鼠标按住移动然后松开的时候,往保存所有移动过的点的列表中添加一个断点(-1, -1)。然后在每次画线的时候,都判断一下是不是断点,如果是断点的话就想办法跳过去,并且不连续的开始接着画线。由此,我们就获取到了鼠标在画板上的轨迹。代码如下:
import sys
from PyQt5.QtWidgets import (QApplication, QWidget)
from PyQt5.QtGui import (QPainter, QPen)
from PyQt5.QtCore import Qt
class Example(QWidget):
def __init__(self):
super(Example, self).__init__()
#resize设置宽高,move设置位置
self.resize(400, 300)
self.move(100, 100)
self.setWindowTitle("简单的画板4.0")
#setMouseTracking设置为False,否则不按下鼠标时也会跟踪鼠标事件
self.setMouseTracking(False)
'''
要想将按住鼠标后移动的轨迹保留在窗体上
需要一个列表来保存所有移动过的点
'''
self.pos_xy = []
def paintEvent(self, event):
painter = QPainter()
painter.begin(self)
pen = QPen(Qt.black, 2, Qt.SolidLine)
painter.setPen(pen)
'''
首先判断pos_xy列表中是不是至少有两个点了
然后将pos_xy中第一个点赋值给point_start
利用中间变量pos_tmp遍历整个pos_xy列表
point_end = pos_tmp
判断point_end是否是断点,如果是
point_start赋值为断点
continue
判断point_start是否是断点,如果是
point_start赋值为point_end
continue
画point_start到point_end之间的线
point_start = point_end
这样,不断地将相邻两个点之间画线,就能留下鼠标移动轨迹了
'''
if len(self.pos_xy) > 1:
point_start = self.pos_xy[0]
for pos_tmp in self.pos_xy:
point_end = pos_tmp
if point_end == (-1, -1):
point_start = (-1, -1)
continue
if point_start == (-1, -1):
point_start = point_end
continue
painter.drawLine(point_start[0], point_start[1], point_end[0], point_end[1])
point_start = point_end
painter.end()
def mouseMoveEvent(self, event):
'''
按住鼠标移动事件:将当前点添加到pos_xy列表中
调用update()函数在这里相当于调用paintEvent()函数
每次update()时,之前调用的paintEvent()留下的痕迹都会清空
'''
#中间变量pos_tmp提取当前点
pos_tmp = (event.pos().x(), event.pos().y())
#pos_tmp添加到self.pos_xy中
self.pos_xy.append(pos_tmp)
self.update()
def mouseReleaseEvent(self, event):
'''
重写鼠标按住后松开的事件
在每次松开后向pos_xy列表中添加一个断点(-1, -1)
然后在绘画时判断一下是不是断点就行了
是断点的话就跳过去,不与之前的连续
'''
pos_test = (-1, -1)
self.pos_xy.append(pos_test)
self.update()
if __name__ == "__main__":
app = QApplication(sys.argv)
pyqt_learn = Example()
pyqt_learn.show()
app.exec_()
实现效果如图所示:

控制板
我在PyCharm中导入了QtDesigner,并添加了Pyuic插件用于将QtDesigner导出的.ui文件编译成python代码。首先,我使用QtDesigner画出了控制板的界面,如下:

接下来在类中导入画板,并获取其轨迹信息,编写各个按钮、显示器的绑定函数。注意,原本训练集测试集的图像大小是28*28,而画板的大小不可能那么小,我采用了400x400的画板,于是映射到28x28的图片上应该将笔记在后台加粗14倍再转为28x28图片再转成张量传入神经网络。最终代码如下:
class Ui_controlBoard(QWidget):
def __init__(self, exampleclass):
# super(Ui_controlBoard, self).__init__()
super().__init__()
self.paintboard = exampleclass
self.boardText = ''
self.net = CNN()
self.net.load_state_dict(torch.load('net_params.pkl'))
self.setupUi(self)
self.show()
def setupUi(self, controlBoard):
controlBoard.setObjectName("controlBoard")
controlBoard.resize(400, 300)
self.pushButton = QtWidgets.QPushButton(controlBoard)
self.pushButton.setGeometry(QtCore.QRect(40, 250, 93, 28))
self.pushButton.setObjectName("pushButton")
self.pushButton_2 = QtWidgets.QPushButton(controlBoard)
self.pushButton_2.setGeometry(QtCore.QRect(150, 250, 93, 28))
self.pushButton_2.setObjectName("pushButton_2")
self.pushButton_3 = QtWidgets.QPushButton(controlBoard)
self.pushButton_3.setGeometry(QtCore.QRect(260, 250, 93, 28))
self.pushButton_3.setObjectName("pushButton_3")
self.textBrowser = QtWidgets.QTextBrowser(controlBoard)
self.textBrowser.setGeometry(QtCore.QRect(40, 40, 321, 161))
self.textBrowser.setObjectName("textBrowser")
self.label = QtWidgets.QLabel(controlBoard)
self.label.setGeometry(QtCore.QRect(40, 20, 72, 15))
self.label.setObjectName("label")
self.lineEdit = QtWidgets.QLineEdit(controlBoard)
self.lineEdit.setGeometry(QtCore.QRect(150, 220, 211, 21))
self.lineEdit.setObjectName("lineEdit")
self.label_2 = QtWidgets.QLabel(controlBoard)
self.label_2.setGeometry(QtCore.QRect(40, 220, 101, 16))
self.label_2.setObjectName("label_2")
self.clearBoardBtn = QtWidgets.QPushButton(controlBoard)
self.clearBoardBtn.setGeometry(QtCore.QRect(300, 20, 61, 20))
self.clearBoardBtn.setObjectName("clearBoardBtn")
self.retranslateUi(controlBoard)
QtCore.QMetaObject.connectSlotsByName(controlBoard)
self.pushButton.clicked.connect(self.clearPaintboard)
self.pushButton_2.clicked.connect(self.myRecognize)
self.clearBoardBtn.clicked.connect(self.clearBoard)
def retranslateUi(self, controlBoard):
_translate = QtCore.QCoreApplication.translate
controlBoard.setWindowTitle(_translate("controlBoard", "controlBoard"))
self.pushButton.setText(_translate("controlBoard", "清空画板"))
self.pushButton_2.setText(_translate("controlBoard", "提交识别"))
self.pushButton_3.setText(_translate("controlBoard", "提交训练"))
self.label.setText(_translate("controlBoard", "状态监视"))
self.label_2.setText(_translate("controlBoard", "手写数字值:"))
self.clearBoardBtn.setText(_translate("controlBoard", "clear"))
def addToBoard(self, text):
self.boardText += text + '\n'
self.textBrowser.setText(self.boardText)
def getPosMatrix(self):
self.addToBoard('已获取手写轨迹坐标点集')
return self.paintboard.pos_xy
def clearBoard(self):
self.boardText = ''
self.textBrowser.setText(self.boardText)
def myRecognize(self):
self.savePaintboardPNG()
testimg = Image.open('handwriteNumber.png')
self.addToBoard('已读取图片handwriteNumber.png')
testimg = changeImage28(testimg)
self.addToBoard('已转换为28*28尺寸图片')
im = testimg.convert("L")
self.addToBoard('已转换图片为灰度格式')
data = im.getdata()
data = np.matrix(data, dtype='float') / 255.0
new_data = np.reshape(data * 255.0, (28, 28))
new_data = new_data[np.newaxis, np.newaxis, :]
t = torch.from_numpy(new_data).type(torch.FloatTensor) / 255.
self.addToBoard('已将图片数据存入tensor,开始传入神经网络...')
output = self.net(t)
self.addToBoard('已获得网络输出')
outputList = output[0][0].tolist()
res = outputList.index(max(outputList))
self.addToBoard('已获取识别结果,识别手写的数字为:' + str(res))
return res
def inZone(self, point):
if max(point)<400 and min(point)>-1:return True
else:return False
def savePaintboardPNG(self):
written = self.getPosMatrix()
matrix = zeros((400, 400))
for point in written:
x = point[1]
y = point[0]
if max(point) < 400 and min(point) > -1:
matrix[x][y] = 1
# 加粗
px = 14
pxPoints = []
stx = x-px
sty = y-px
for i in range(2*px):
for j in range(2*px):
pxPoints += [[stx+i, sty+j]]
for p in pxPoints:
if self.inZone(p):
matrix[p[0]][p[1]] = 1
narray = np.array(matrix, dtype='int')
img = Image.fromarray(narray * 255.0)
img = img.convert('L')
img.save('handwriteNumber.png')
self.addToBoard('已保存为PNG格式')
def clearPaintboard(self):
self.paintboard.pos_xy = []
至此,已成功实现了这个程序提交识别的全部功能,可以尝试着让它识别你的手写数字了:


